
无论是离线数仓依然及时数仓,皆是企业为业务有打算、数据分析提供褂讪的数据复古。关联词关于不同的业务和数据时效条款,他们两个架构设想的逻辑是不雷同的。
今天就跟专家聊聊离线数仓和及时数仓是什么?把他们的区别给专家讲了了,聊显豁。
一、先把数仓的中枢逻辑说了了
数据仓库,本体上是一个面向分析的数据存储和加工体系。它的中枢主义即是提供清澈、易用、高质地的数据展现层,工作于报表、分析和业务有打算。
许多东谈主一运行会把数仓和数据库同日而论。
数据库是用来复古业务系统运行的,强调写入性能和事务一致性。
数仓是用来复古数据分析的,强调读取性能和历史数据的完整性。
两者的设想主义从根上就不同,不可混用,也不可彼此替代。
数仓征战的第一个要津行动是分层。分层的中枢原则是每一层只作念我方该作念的事,数据加工逻辑清澈,层与层之间使命界限明确。这么作念的公正是:
复杂问题被拆解成多个浅易法子,每一步皆不错颓落考据;
数据不错在层间复用,幸免相易征战;
出了问题不错快速定位到具体哪一层,不需要从新排查整条链路。
二、离线数仓,打褂讪批量处理
离线数仓中枢是按固定周期批量处理数据,主流处理时效为T+1,部分低频分析场景会用到T+7。其架构设想的中枢围绕分层设想和维度建模伸开,这两大中枢决定了离线数仓的可用性和可诊疗性。
1. 分层设想
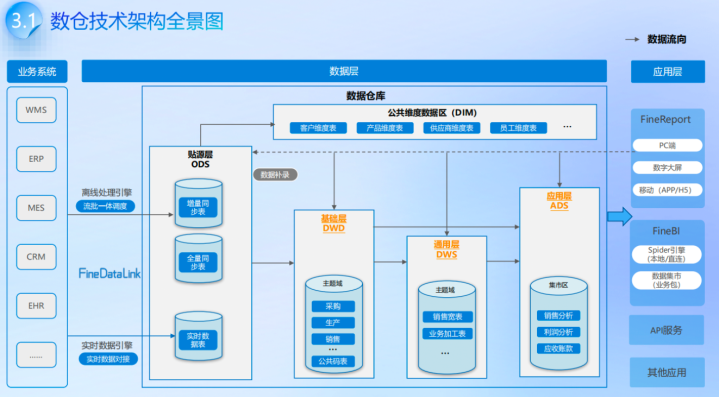
离线数仓的分层盲从高内聚、低耦合的原则,每个层级皆有明确的作用域,既能收场数据血统跟踪,又能减少相易征战,把复杂的数据处理问题拆分红浅易的法子。表率的分层结构如下:
ODS层是数仓的数据进口,对接业务库、日记、爬虫、三方接口等各样数据源,用DataX、Sqoop等器用收场T+1的全量或增量同步,这一层只作念原始数据的快照存储,不作念任何清洗和加工,保留数据最原始的景色,为后续数据问题回溯提供依据。
DWD层是数据表率化中枢层,对ODS层的原始数据作念清洗、去重、调和方法、维度退化等处理,还会依据数据属性永别为事实表和维度表,这一层的处理质地径直决定了后续数仓数据的准确性,亦然通盘这个词离线数仓的基础。
DWS层是民众汇总层,对DWD层的明细数据作念轻度团聚,整合为某一业务主题域的宽表,能大幅提高卑劣的查询成果,减少相易计算。
ADS层是径直面向业务的哄骗层,将DWS层的团聚数据加工为各样业务打算,供居品、运营、数据分析东谈主员使用,亦然日报、周报、月报等固定报表的数据开头。
DIM维度层单独存储各样维度数据,包括期间维表、地域维表、商品维表等,为其他各层的维度联系提供复古,分为高基数和低基数维度数据,适配不同的联系需求。
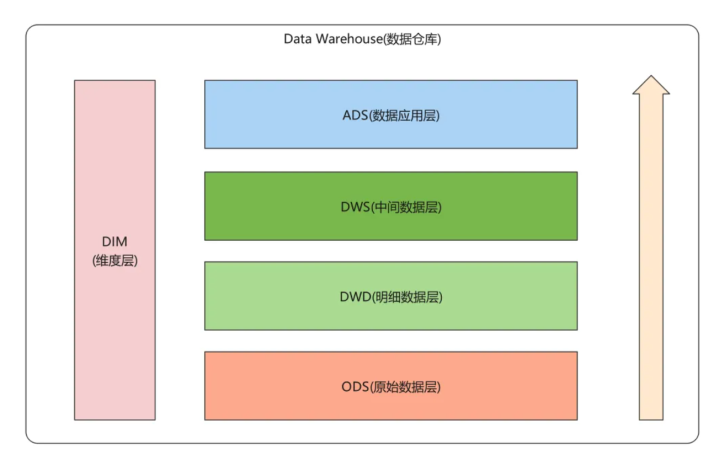
2. 维度建模
分层设想治理了数据处理的经由问题,维度建模则治理了数据的组织问题,让数据更贴合企业的业务分析逻辑。
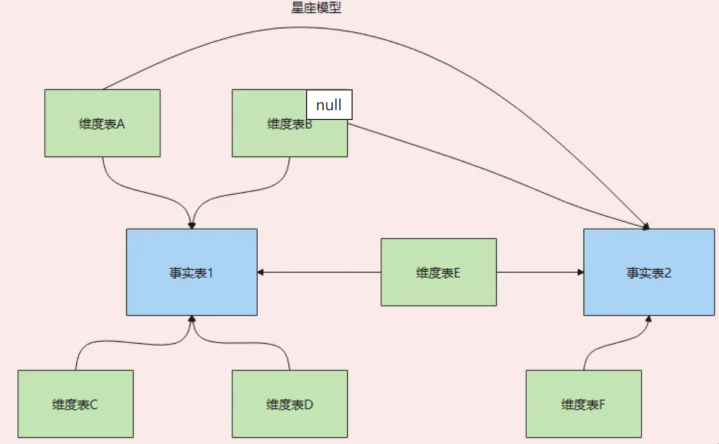
离线数仓的主流建模设施是维度建模,常用的模式有星型、雪花型和星座型,其中星座型模式是企业最常用的,基于多张事实表分享维度信息,能适配企业多业务主题的分析需求。
星型模式以单张事实表为中枢,通盘维度表径直联系事实表,结构浅易、查询成果高;
雪花模式是星型模式的扩张,维度表不错联系其他维度表,更表率但诊疗资本高、查询性能差,试验哄骗中很少用到;
星座模式基于多张事实表,且分享维度信息,完满贴合企业多业务、多主题的分析场景,亦然离线数仓建模的首选。
除此以外,离线数仓的征战回有明确的实战经由,从需求分析调研、数据探查,到模子设想、ETL征战,再到数据考据、任务调度和上线不停,每一步皆有严格的表率,比如事实表的粒度要调和、度量需为可加性数值,出产环境的表名和字段定名要盲从调和握法,这些细节皆是保证离线数仓永恒褂讪运行的要津。
三、及时数仓,主打低延迟流式处理
及时数仓是跟着企业及时化业务需求发展而来的,比真正时权谋大屏、即时推选、用户步履及时候析等,这些场景对数据时效的条款远高于T+1,秒级到分钟级的延迟是中枢需求,这亦然及时数仓存在的核情意旨。
浅易来说,及时数仓的中枢是低延迟处理流式数据,其架构从底层数据源接入到表层计算、存储皆作念了全新的设想,阅历了从初期的“烟囱式征战”到咫尺的Lambda、Kappa,真钱三公app官方最新版下载再到流批集结架构的演变。
1. 主流架构:Lambda、Kappa与流批集结
咫尺企业常用的及时数仓架构主要有三种,分别是Lambda、Kappa和流批集结架构,各有其设想逻辑和适配场景。
Lambda架构:分为及时计算和离线计算两条线。
及时计算层通过流式引擎处理最新的流式数据,得志低延迟需求;离线计算层批量处理全量数据,保证数据准确性,临了将两层罢休会通输出。
这种架构稳健对数据准确性条款极高的场景,比如往复金额统计、财求及时打算,但短处也很彰着,需要诊疗两套计算体系,征战和诊疗资本皆比拟高。
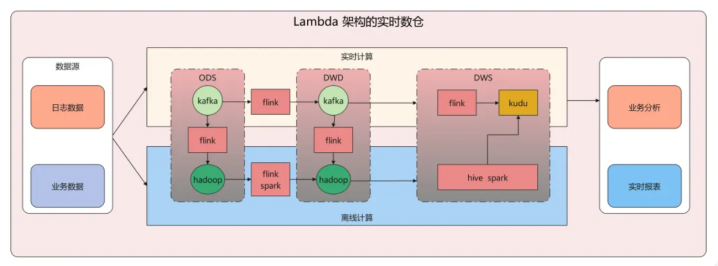
Kappa架构:只用一套流式计算引擎处理所罕有据。
通过重放日记来收场全量数据的回溯计算,架构更通俗、征战资本更低,稳健大部分企业的及时候析场景。而Flink这类流式计算引擎治理了数据乱序、迟到的问题,也让Kappa架构的落地成为可能。
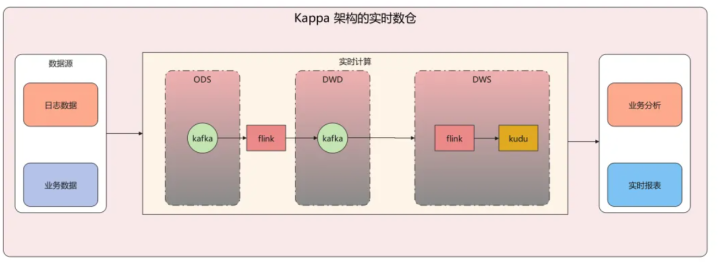
流批集结架构:这是咫尺及时数仓的发展趋势,集结了Lambda和Kappa的上风。
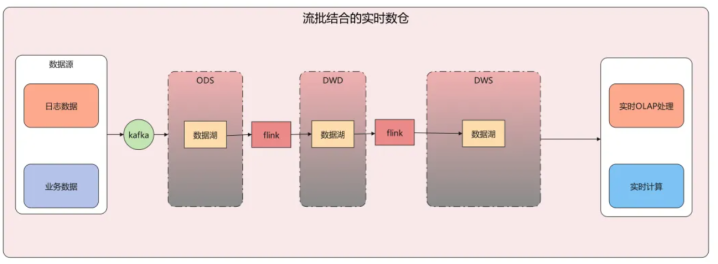
依托数据湖的ACID才智简化架构设想,既保证了数据的及时性,又能镌汰数据处理的延迟,还能收场数据的修改、删除,让及时数仓的纯真性和可用性大幅提高。
2. 分层设想:全程流式处理
和离线数仓雷同,及时数仓也盲从ODS、DWD、DWS、ADS的分层设想,但各层的收场表情、技艺选型和处理逻辑十足不同,全程围绕流式处理伸开。
及时ODS层通过Flink CDC、Flume、Logstash等器用,将业务库binlog、及时日记、埋点数据及时接入Kafka,数据以流的方法存储,而非离线数仓的静态文献;
及时DWD层通过Flink作念流式ETL,及时完成数据清洗、表率化和维度联系,同期处理数据乱序、迟到等问题,输出干净的及时明细数据;
及时DWS层通过Flink的窗口团聚功能,对明细数据作念秒级或分钟级的及时团聚,将罢休写入ClickHouse、Doris等及时OLAP器用;
及时ADS层基于及时OLAP器用提供的打算,径直复古及时大屏、及时查询、及时风控等业务场景,收场数据的即时输出。
四、中枢各异与选型逻辑
用过来东谈主的素质告诉你,最中枢的各异体咫尺数据处理表情和时效上,而技艺选型、架构复杂度、诊疗资本皆是基于这个中枢各异延长而来的。
离线数仓是批量、周期性处理,时效T+1,技艺选型以Hive、Spark、DataX为主,架构浅易、诊疗资本低,稳健历史数据分析、固定报表统计、财务对账等对时效条款不高的场景;
及时数仓是流式、不隔断处理,时效秒级到分钟级,技艺选型围绕Kafka、Flink、ClickHouse等器用搭建,需要处理数据乱序、景色不停等问题,架构更复杂,7×24小时运行也让诊疗资本远高于离线数仓,稳健及时监控、动态有打算、即时推选等对数据时效有强需求的业务场景。
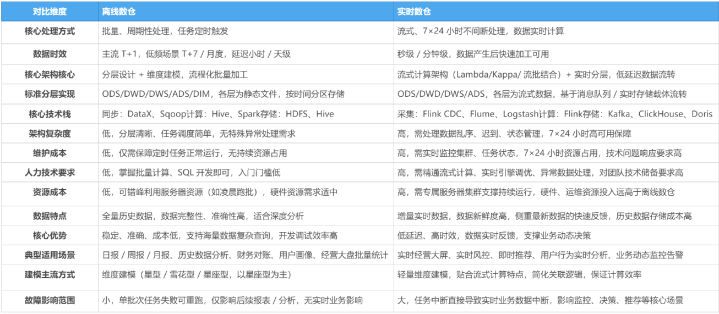
可能有东谈主会问,咫尺流批一体是趋势,是不是及时数仓会十足替代离线数仓?其实否则,两者各有其适配的场景。怎么选?不错从这几个方面分析:
看时效性条款。 业务能收受T+1的数据,优先离线数仓,资本低、褂讪性高、征战成果高。业务需要分钟级甚而秒级数据,及时数仓是必须的,莫得筹议余步。
看团队技艺储备。 及时数仓对团队的技艺条款彰着高于离线数仓。若是团队在流处理方面素质不及,贸然上及时数仓,踩坑的概率极高,焉知非福。
看预算和资源。 及时数仓的资源资本和东谈主力资本皆高于离线数仓。预算有限的情况下,把离线数仓作念塌实,比什么皆紧迫。
看数据量级和查询复杂度。 数据量极大、查询逻辑复杂的场景,离线批处理的上风更彰着。数据量相对可控、查询模式固定的场景,及时数仓更容易落地。
大大皆公司的试验情况是离线和及时并存,各自工作不同的场景,两者是互补关系,不是替代关系。
而流批一体的数仓体系,恰是基于这种互补关系发展而来的行业将来地方,用一套技艺栈同期复古离线和及时处理,既保证了数据口径的调和,又能镌汰征战和诊疗资本。 咱们团队用的即是FineDataLink ,它能完满适配流批一体的数仓征战需求,收场一套器用复古离线批量集成和及时流式集成,无需切换多套器用,极大镌汰了流批一体数仓的征战和诊疗资本。
临了
数仓架构的演进,从离线到及时真钱三公app官方最新版下载,从Lambda到Kappa,再到流批集结和湖仓一体,背后皆是业务需求在驱动。技艺选型的背后,是对业务需求、团队才智、以及资本和收益的深远默契和评估。把这三件事念念了了,架构的遴荐当然就清澈了。
2026世界杯官方网站 备案号:
备案号: