
昔日几年,外界和洽NVIDIA,频频从 GPU、CUDA、检会集群这些要道词切入。但在本年,这套施展框架照旧发生了变化。
在GTC 2026运转前,老黄发布了一篇“AI五层蛋糕”的签字著作。在“五层蛋糕”的体系中,老黄再行给出了AI的坐标系——最底层是动力层,负责提供适当、可调理的及时电力;往上是芯片层,将能量高效转动为盘算;再往上是基础设施层,把千千万万的处理器组织成一个可调理的举座,也便是“AI工场”;其上是模子层,承载谈话、物理、生物、化学等基础模子;最表层才是应用层,完成最终的价值变现。
正因为成见发生了迁徙,是以关于本年的GTC 2026,我和洽NVIDIA在抒发其围绕算力坐褥与录用形状的系统性逻辑。沿着“五层蛋糕”张开,不错看到NVIDIA的自我定位运转转向为AI工场的全栈架构设想者。
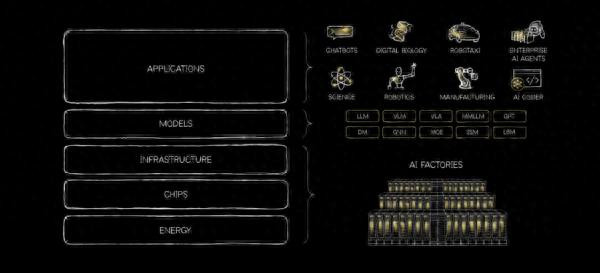
01 “五层蛋糕”是和洽GTC 2026的进口
如若要为GTC 2026找一个和洽的进口,“五层蛋糕”是退却易走偏的一条。
老黄在签字著作里先给了一个前提判断:盘算范式照旧发生变化。昔日的软件是预制逻辑,数据被整理为结构化表格,通过精准查询完成调用;而今天的 AI,处理的辱骂结构化信息,基于高下文与意图进行推理,并及时生成闭幕。既然“智能”不再是事前写好的代码,那么支柱它的整套盘算体系,也就不成能沿用旧架构。
在这个前提下,他给出了“五层蛋糕”框架。
用这一框架看GTC 2026上NVIDIA的发布,就不丢脸出,这些差别的家具线,是围绕团结成见张开的——在功率受限成为常态的前提下,将数据中心转动为高浑沌、低时延、可不绝运行的“token坐褥系统”。
由此带来的变化,是评价体系的迁徙。行业暖热要点从单卡性能、互联带宽与集群领域,转向单元功率下的token产出、时延适当性与系统欺诈率。
沿着这一逻辑,电力接入、液冷系统、机房形态、施工与部署节律、仿真考据,再到模子检会与推理调理等原天职散的身分运转被统一纳入团结设想框架。这种从基础设施到表层应用的举座协同,被NVIDIA称为extreme codesign(深度协同设想),骨子上是对全链路进行统一优化。
这一标的在Rubin平台早期阶段照旧有所体现。其时强调的是系统里面六大中枢芯片的协同设想:Vera CPU、Rubin GPU、NVLink 6 Switch、ConnectX-9 SuperNIC、BlueField-4 DPU、Spectrum-6以太网交换机,措置的是盘算系统里面的组织形状。而在GTC 2026上,这一协同被进一步外延,与DSX、Dynamo、STX、Nemotron等软件与模子体系筹划,举座纳入AI工场的统一框架之中。
因此,“五层蛋糕”的好奇瞻仰好奇瞻仰,就成为了“建立统一的模范”。
02 动力层:AI工场的“第一性管制”,落到了每瓦token的产出
“五层蛋糕”中信得过决定下限的一层,其实是动力。
老黄在签字著作里的表述异常清爽:每一个token的生成,骨子上都是电子流动、热量管理以及能量向盘算转动的过程。在这一层之下,并不存在进一步的空洞层。这一判断的好奇瞻仰好奇瞻仰在于,把AI再行放回到一个工业系统之中来和洽,不再只是模子、参数与评测成见,而是回到供电、散热与工程实现这些更基础、也更刚性的维度。

从这个视角看,将来几年信得过拉开差距的,很可能不是谁的模子更大,而是谁粗略更高效地使用“电”。
而这种才调,取决于电网接入、冷却形状、成立周期,以及开采录用等一整套条目,最终体现为单元时刻内可不绝输出的盘算才调。
在GTC 2026上,NVIDIA给出的搪塞想路是向系统层发力。
一个比拟直不雅的变化,是机架级形态正在围绕液冷被再行界说。Vera Rubin系统照旧实现了100%液冷,并引入高温水冷设想,一方面压缩部署周期,另一方面把原来花消在制冷上的能量尽可能让渡给盘算。
这是在再行分拨数据中心里面的能量结构。
但更值得谨防的,是另一条更偏“运营侧”的旅途。NVIDIA将“AI工场”行动了不绝运行、不绝调整的系统来对待。
围绕这少量,NVIDIA在GTC 2026上推出了NVIDIA Omniverse DSX Blueprint,以及Vera Rubin DSX AI Factory参考设想,把tokens per watt、time to first production(每瓦Token 数 / 单元功耗Token浑沌量),以及系统韧性等成见放在团结套框架下,同期将机架、电气、热管理、网罗乃至运行政策,也放进了团结个设想与优化系统中。
生态的组成也印证了这少量。在DSX这套体系中,不同合作伙伴的脚色,对应AI工场从设想到运行的不同设施。Cadence、Dassault Systèmes、PTC、Siemens这类公司,措置的是“设想”的问题,NVIDIA用AI加持他们的建模与仿真才调,把机房结构、供配电旅途、气流组织等复杂系统,先在数字天下里好意思满推演一遍,提前看到性能与能效的闭幕。
而Trane、Vertiv、Schneider Electric则对应“奈何建出来”。冷却系统如何落地、供电系统如何部署、整套基础设施如何适当运行,这一层决定的是AI工场能否信得过参加使用。
再往后一层,Phaidra、Emerald AI这类合作伙伴处理的是,“建成之后如何不绝跑得更好”。其通过及时数据去调整功率分拨、冷却政策和负载节律,让系统在不同工况下都尽量接近最优情景。
把这三部分连在通盘看,就会发现DSX想作念的事情,是把“设想—成立—运行”这三段彼此割裂的历程捏住到团结套体系中。这么一来,许多原来只可在建成之后再渐渐试错的问题,不错提前在设想阶段被考据,投注平台而运行阶段的优化劝诫,也不错反过来修正设想本人。。
在这一框架下,NVIDIA发布DSX Sim、DSXMax-Q、DSXFlex等软件的价值,便是在数字孪生环境中,把功率、冷却与网罗耦合起来,通过不绝调优去实现更高效的运职业态。
03 芯片层:把算力变成可录用的坐褥单元
顺着“五层蛋糕”去和洽,芯片层的好奇瞻仰好奇瞻仰便是把电力高效转动为盘算才调的任务,其决定AI能扩到多大领域,也决定智能能否进入更平时、更低资本的应用场景。
从更新的时刻和家具中,也能看出这层好奇瞻仰。
1、Vera Rubin NVL72:机架成为芯片层的基本录用单元
Vera Rubin NVL72集成了72颗Rubin GPU,36颗Vera CPU,ConnectX-9 SuperNIC和BlueField-4 DPU。机架里面通过NVLink 6纵向扩张,机架之间通过Quantum-X800 InfiniBand与Spectrum-X Ethernet横向扩张,可平直作为AI工场模块接入。
参数上,Rubin NVL72提供3600PFLOPS NVFP4推感性能、2520PFLOPS NVFP4检会性能,配备20.7TB HBM4、1580TB/s HBM带宽和260TB/s NVLink总带宽。单颗Rubin GPU则对应50PFLOPS NVFP4推理、288GB HBM4和22TB/s HBM带宽。
这套界说强调的是机架级浑沌、内存驻留和互连密度。对长高下文模子、MoE模子和大领域推理干事来说,信得过影响系统上限的是整机架里面能否造成适当的高带宽数据旅途。NVL72把GPU、CPU、网卡和DPU固定进团结系统单元,让录用形态成为可平直部署的智能坐褥单元。
2、Rubin GPU:HBM4、NVFP4和Transformer Engine面向推理链路
Rubin GPU的升级要点积存在HBM4、NVFP4和Transformer Engine。对应到现时模子演进,中枢问题照旧落在内存容量、内存带宽、低比特现实成果和高下文处理才调上。
单颗Rubin GPU配备288GB HBM4,带宽达到22TB/s。HBM容量关系到模子参数、激活和KV cache的驻留领域,HBM带宽决定长高下文推理、检索增强和多轮Agentic交互中的数据探访成果。
NVFP4照旧写进推理和检会的显式规格,阐明低精度旅途进入主战才调范围。配合Transformer Engine、张量中枢和软件栈,成见是不绝压低单元token的盘算资本,在可领受精度下磋议更高浑沌和更低推理资本。
从Hopper的FP8,到Blackwell,再到Rubin的NVFP4,NVIDIA的道路照旧很明确——便是要把低比特精度、张量中枢和内存旅途整合起来,干事推理、Agentic AI和长高下文推理等负载。
3、Vera CPU:承担Agentic系统的扫尾与调理
Vera CPU面向Agentic AI和强化学习设想,选拔88个Olympus中枢,通过NVLink-C2C提供1.8TB/s一致性互连带宽,并针对数据转移、Agentic reasoning和笃定性性能作念优化。
这类设想对应的是AI系统运行形状的变化。今天的Agentic系统除了前向推理,还包含器具调用、文献探访、情景休养、任务拆解、浏览器操作、环境交互、并发调理和强化学习rollout。CPU要不绝处理扫尾流和系统级调理,地位照旧接近扫尾面处理器。
88个中枢面向大领域并发扫尾,1.8TB/s NVLink-C2C则把CPU与GPU之间的数据交换拉进更高带宽、更低蔓延的一致性结构。这关于Agentic runtime、数据预处理和强化学习轮回来说,这种互连形状平直关系到情景分享和现实成果。
4、ConnectX-9 SuperNIC与BlueField-4 DPU:网罗和数据平面进入主现实链路
ConnectX-9 SuperNIC和BlueField-4 DPU直领受入芯片层界说,阐明网罗和数据平面照旧进入了主现实链路。
ConnectX-9 SuperNIC为每颗GPU提供1.6Tb/s带宽,并支柱可编程RDMA和低时延GPU 直连网罗(GPU-direct networking)。对踱步式检会和推理来说,这关系到GPU间通讯、远端存储探访、参数交换和跨节点KV cache同步的成果,最终会平直反馈到token时延和系统欺诈率。
BlueField-4 DPU则负责把存储、网罗、安全、弹性扩张等数据处理负载从CPU和GPU主旅途中卸载出来,真钱三公并邻接探访扫尾、田户进犯、DMA管理、左券栈处理和数据旅途优化。
5、Groq 3 LPU/LPX:补都低时延推理区间
Rubin家具体系里另一个值得谨防的变化,是新纳入了Groq 3 LPU与Groq 3 LPX rack。其界说是为面向低时延、长高下文Agentic systems的推理加快器。
性能上看,单机架256个LPU、128GB SRAM、40PB/s memory bandwidth和640TB/s scale-up bandwidth,并能与Vera Rubin NVL72的协同设想。
这意味着悉数体系运转障翳两类推理区间。一类由Rubin NVL72邻接,面向高浑沌、大容量、长高下文和大模子主体负载;另一类由Groq 3 LPX邻接,面向更强调反当令刻的低时延推理链路。
两类处理器对应不同成见。Rubin更瞻仰大领域并行、超大内存容量和机架级互连;Groq 3 LPX更强调高带宽SRAM、笃定性现实旅途和局部数据流扫尾。
将其放进AI工场后,底层算力系统就能按高浑沌、低时延、长高下文和扫尾调理等不同任务单干协同。
04 基础设施层:把算力组装成“AI工场”
如若说上一层措置的是“AI工场由哪些芯片组成”,那么基础设施层要措置的,便是这些芯片若何被组织起来,信得过变成一套粗略不绝运行的工场级机器。
按照老黄“五层蛋糕”的说法,芯片只是把动力转成智能的中枢部件,但要把这种调动适当放大到大领域推理、长高下文处理和Agentic系统运行,光有GPU、CPU和DPU还不够,必须再往上搭起互连、网罗、存储和安全组成的基础设施底盘。
沿着这个想路往下看,基础设施层的几项更新其实都指向团结个成见——在更大的系统模范上造成统一盘算体。这少量也体面前具体的家具更新上。
1、NVLink 6把机架内互连变成统一的“骨干”
领先被推到最中枢位置的,是NVLink 6。、每颗Rubin GPU具备3.6TB/s的all-to-all scale-up带宽,Vera Rubin NVL72整机架总NVLink带宽达到260TB/s。放在平台界说里,这是在为机架里面建立一套统一的高速盘算骨架。
这少量和前边的芯片层是连在通盘的。既然Vera Rubin NVL72照旧把72颗Rubin GPU、36颗Vera CPU、ConnectX-9 SuperNIC和BlueField-4 DPU固定成一个机架级系统,那么接下来信得过决定这套系统是否成立的,便是机架里面能否守护一个阔气大、阔气适当的低时延高带宽scale-up域。
对长高下文模子、MoE模子和多阶段推理来说,系统上限频频领先撞上的便是这层互连才调。因此NVLink 6在Rubin这一代承担的脚色,更接近机架内骨干,而不是普通好奇瞻仰好奇瞻仰上的芯片间流通。至于机架之间的不绝扩张,则由Quantum-X800 InfiniBand和Spectrum-X Ethernet去完成。
2、Spectrum-6 SPX与Spectrum-X Ethernet Photonics:网罗扩张运转拼能效和韧性
再往外一层,基础设施层要措置的,是这些机架级盘算单元若何以更低损耗、更高韧性的形状不绝向外扩张,最终拼成更大的AI工场。
这背后的工业逻辑很平直。AI工场领域一朝不绝放大,瓶颈很快就会从单颗芯片性能,转移到机架到机架之间的网罗系统本人,包括交换侧功耗、光模块功耗、布线复杂度、故障率、休养可达性,以及整套网罗的TCO。
在这一层,Spectrum-6 SPX Ethernet rack 承担的是机架级网罗录用单元的脚色,负责 AI 工场里面大领域 east-west 流量的低时延、高浑沌互连,其可设立为基于Spectrum-X Ethernet、Quantum-X800 InfiniBand交换体系。与此同期,Spectrum-X Ethernet Photonics 进一步把共封装光学引入交换侧,用来提高光互连的能效和网罗韧性。
3、BlueField-4 STX把存储拉进推理主链路
当机架里面互连和机架外部网罗都进入平台后,基础设施层接下来的变化就落到了存储上。
GTC 2026里一个异常迫切的更新,便是BlueField-4 STX。这是面向AI-native data platform的模块化参考架构,用来匡助企业、云厂商和AI干事商部署加快存储基础设施,支柱Agentic AI所需要的长高下文推理。
基于这套架构的新一代推理存储平台可实现最高5倍token浑沌、最高4倍能效,以及2倍更快的数据领受;首批选拔方包括CoreWeave、Crusoe、IREN、Lambda、Mistral AI、Nebius、OCI和Vultr。
现时模子演进越来越强调长高下文、Agent现实、多器具调用和检索增强,这意味着系统压力不单落在HBM和NVLink,也会落到高下文历久化、向量检索、日记与轨迹存储、学问库探访以及大领域非结构化数据浑沌上。
而芯片层措置的是“算得动”,到了这一层还要不绝措置“喂得上”。
4、Confidential Computing把安全“焊”进基础设施底盘
在互连、网罗和存储以外,Rubin基础设施层终末补上的,是安全鸿沟。
这个问题在大模子时期尤其敏锐。
模子权重、微调闭幕、迥殊数据和Agentic现实日记,本人都是高价值钞票,云上多租、主权部署、行业进犯部署和腹地部署又都在增长。
而莫得硬件级奥妙盘算,许多受监管行业和高安全要求场景都很难信得过把AI系统放进坐褥环境。
是以,Confidential Computing放到基础设施层里,是在告诉企业不错在有进犯、有鸿沟要求的环境里运行。
05 模子层:怒放生态+ Agentic、Physical与Healthcare三向扩张
到了模子层,值得谨防的是NVIDIA隆重推出了Nemotron Coalition。这是由怒放模子构建者与AI开发者组成的寰球相助体系,通过分享征询、专科学问、数据与算力,激动open frontier models。
首批成员包括 Black Forest Labs、Cursor、LangChain、Mistral AI、Perplexity、Reflection AI、Sarvam 和 Thinking Machines Lab。
这件事的好奇瞻仰好奇瞻仰,更像是在在搭建怒放生态,把不同区域、不同模态、不同垂直领域的模子眷属不绝往外长,而这些模子不绝增万古,底层锚定在NVIDIA的算力与运行时体系上,其中包括DGX Cloud、CUDA、TensorRT、NIM。
怒放模子越强,迥殊部署、行业定制和主权AI的需求就越强,基层GPU、网罗、存储与运行时的需求也会被同步放大。Nemotron Coalition骨子上承担的是“把怒放模子茂密,转动成基础设施投资”的机制。
另外NVIDIA还扩张了怒放模子眷属,标的积存在Agentic AI、physical AI 和 healthcare AI。
Agentic一侧包括CodeRabbit、CrowdStrike、Cursor、Factory、ServiceNow、Perplexity;;physical AI一侧包括 LG Electronics 和 Milestone Systems;healthcare一侧则包括Novo Nordisk、Viva Biotech 和 Manifold Bio。
06 应用层:把AI才调实现为坐褥力
放在“五层蛋糕”的框架里看,NVIDIA把应用层界说成 AI工业体系里最接近真是坐褥力的一层。动力、芯片、网罗、基础设施决定的是上限,信得过把这些才调变成行业成果、企业ROI 和可不绝采购原理的,如故应用层。
也正因为如斯,老黄在GTC上反复强调CUDA-X是NVIDIA的crown jewels。沿着这条线看,GTC 2026的应用层至少开释了两个很强的信号。
第一个信号,是结构化与非结构化数据处理,照旧被NVIDIA明确纳入AI时期的基础才调。老黄在演讲里把SQL、Spark、Pandas、Velox、Snowflake、Databricks、BigQuery、Fabric、EMR放进团结张图,强调结构化数据正在为AI提供高下文,并超越点出cuDF和cuVS的平台价值。
这个信息很迫切,阐明NVIDIA对企业AI的和洽进一步激动到了数据处理、向量检索和RAG数据平面这一层。
这背后的行业判断是,企业AI一朝从试点走向永恒运行,资本结构很快就会发生变化。决定系统能否落地的,是企业里面大都表格、日记、PDF、视频、语音等数据,能否被快速整理、索引、检索并转成模子可消费的高下文。
也便是说没,谁能把这一层作念到高浑沌、低时延、低资本,谁就能在企业AI的坐褥阶段占住要道位置。CUDA-X的价值也正在这里体现出来,其可将算力折算成查询时刻、索引成果、检索速率和举座资本的闭幕。
第二个信号,是Agentic AI运转领有荒芜的运行才调。Agent正在从模子外的一层“交互封装”,演进为可部署、可管理、可扩张的系统对象。
在GTC 2026上,这条线最中枢的更新来自Dynamo 1.0、OpenClaw、NemoClaw和OpenShell。NVIDIA将Dynamo 1.0界说为面向大领域生成式与Agentic推理的开源操作系统,这一定位的要道在于——把推理调理、并发现实、高下文管理、跨硬件协同以及工场级运行,整合进一层更高阶的系统软件中。
与此同期,NemoClaw与OpenShell补都了现实侧的另一半才调。OpenShell对应运行环境,OpenClaw对应Agent框架,NemoClaw则负责模子接入、阴私与安全扫尾。
当这几层被串联起来之后,Agent就不再只是调用模子API、拼接器具链的轻量封装,而运转具备长人命周期、腹地现实环境以及清爽的安全鸿沟,缓缓成为信得过好奇瞻仰好奇瞻仰上的“系统单元”。
应用层的另一部分变化,体面前图形时刻与腹地AI的筹划上。DLSS 5、RTX PC、DGX Spark、DGX Station放回NVIDIA的顺次论中,骨子便是应用层如何向腹地环境踱步。
以DLSS 5为例,其把“NVIDIA式的可控生成”具象化地展示出来——由笃定性的3D结构提供鸿沟,再由生成模子补充光照、材质和细节。这种“结构管制+生成补全”的范式,并不单是属于图形渲染,在工业仿真、数字孪生、机器东说念主检会以及物理AI数据生成中,相似不错复用,结构负责笃定鸿沟,生成负责填充复杂性。
而RTX PC、DGX Spark、DGX Station的好奇瞻仰好奇瞻仰,则在于把Agent和怒放模子的运行层,从数据中心拉回到个东说念主开采与使命站中。
NVIDIA在此次GTC上明确强调,OpenClaw及相干怒放模子照旧不错在RTX PC、DGX Spark等系统上腹地运行。这意味着,将来的应用层不会只存在于云霄API之上,而是会踱步在个东说念主结尾、企业迥殊环境以及腹地使命流之中。关于触及阴私、权限扫尾、低时延以及不绝交互的任务来说,腹地运行本人便是应用才调的一部分。
再往下延展,Physical AI其实不错被视为应用层的外延。在GTC 2026中,Isaac、Cosmos、GR00T,以及Open Physical AI Data Factory Blueprint的更新,透露出NVIDIA正在将机器东说念主与自动驾驶相干的软件栈,重组为一条好意思满的“坐褥链”。
在这一体系中,障翳了天下模子、仿真框架、机器东说念主基础模子、数据生成与评估的一整套系统才调。机器东说念主场景对应用层的要求更高,因为它必须同期邻接模子、数据、仿真、扫尾以及边际部署。
也正因如斯,Physical AI成为NVIDIA全栈协同才调最积存的落点之一。
汽车与工业软件标的相似盲从这一逻辑。CUDA-X、Omniverse、DRIVE、Hyperion等家具,运转更好意思满地镶嵌设想、仿真、考据、检会到部署的全历程。
关于车厂和制造业企业来说,应用层信得过需要的真钱三公棋牌官网,是一条从研发到现实的一语气加快链,而不是多少彼此割裂的软件器具。
快乐彩正版app下载官网 备案号:
备案号: